百度蜘蛛,英文名:BaiduSpider。它像一只尋找獵物的蜘蛛,爬行在巨大的互聯(lián)網(wǎng)上搜索自己的目標(biāo),非常生動(dòng)卻又陌生。不管你是一名seo從業(yè)人員還是愛(ài)好者,都在試圖掌握百度蜘蛛的喜好和行蹤,嘗試如何把它吸引過(guò)來(lái)、如何把它服務(wù)好、如何引導(dǎo)它的行走路線、如何把它留下來(lái)。深入了解百度蜘蛛,是做好百度搜索引擎優(yōu)化的重點(diǎn)。
怎么了解自己的網(wǎng)站是否有蜘蛛來(lái)抓取過(guò)?
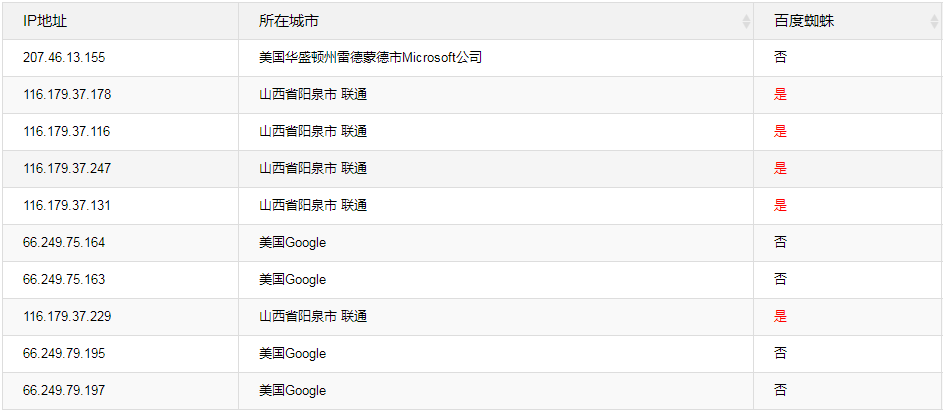
網(wǎng)站主機(jī)的“網(wǎng)站日志->訪問(wèn)日志”里有各種到訪信息,有普通用戶訪問(wèn)信息、有各種搜索引擎的訪問(wèn)信息、甚至電商平臺(tái)的訪問(wèn)信息都可能有。我們把它下載到本地,用記事本打開(kāi)搜索“ Baiduspider/2.0”,如果有百度蜘蛛爬過(guò)會(huì)搜到相關(guān)信息,比如下面這段內(nèi)容就是搜索引擎抓去了http://m.sjzshuzhi.cn/a/archive_show_6_69.html,留下的爬行痕跡[07/Aug/2024:16:37:18 +0800] "GET http://m.sjzshuzhi.cn/a/archive_show_6_69.html HTTP/1.1" 200 5757 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" "m.sjzshuzhi.cn" "text/html" "/data/user/htdocs/a/archive_show_6_69.html" 0.000 - 116.179.37.213
繼續(xù)解讀上面百度蜘蛛留下的信息:(1)爬行時(shí)間[07/Aug/2024:16:37:18 +0800],即2024-8-7 16:37:18;(2)爬行頁(yè)面http://m.sjzshuzhi.cn/a/archive_show_6_69.html;(3)百度蜘蛛標(biāo)志Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html);(4)百度蜘蛛IP:116.179.37.213,屬地:中國(guó)山西陽(yáng)泉 聯(lián)通。116.179.37.*?百度蜘蛛主要用于訪問(wèn)和收集互聯(lián)網(wǎng)上的網(wǎng)頁(yè)、圖片、視頻等內(nèi)容,然后分門別類建立?索引數(shù)據(jù)庫(kù),使用戶能在百度搜索引擎中搜索到您網(wǎng)站的網(wǎng)頁(yè)、圖片、視頻等內(nèi)容。
目前對(duì)百度蜘蛛的各IP號(hào)段說(shuō)法不一,貼出來(lái)僅作參考。
1)抓取你網(wǎng)站的網(wǎng)頁(yè)蜘蛛
60.172.229.61、61.129.45.72、61.135.162.*
2)百度競(jìng)價(jià)蜘蛛
61.135.165.134、117.34.74.66、118.122.188.194、119.63.196.9、125.39.78.185
3)百度統(tǒng)計(jì)的蜘蛛
61.135.186.*
4)站長(zhǎng)工具的模仿的百度蜘蛛
61.147.98.146、61.188.39.16、113.98.254.245、117.21.220.245、117.28.255.42
5)搜外站長(zhǎng)工具的模仿的百度蜘蛛
124.248.34.52
6)114站長(zhǎng)工具箱模仿的百度蜘蛛
119.147.114.213、121.10.141.*
7)百度圖片蜘蛛
123.15.**.**
8)抓取網(wǎng)站內(nèi)頁(yè)收錄的權(quán)重較低的非原創(chuàng),需要通過(guò)一段時(shí)間考察
123.125.71.*
9)站長(zhǎng)工具檢測(cè)造成的無(wú)用
125.90.88.*
10)百度考察期蜘蛛或降權(quán)蜘蛛
159.226.50.*、180.76.5.*、180.76.5.87、220.181.158.107
11)偽裝百度蜘蛛
180.149.130.*
12)新站及站點(diǎn)有不正常現(xiàn)象
183.91.40.144、203.208.60.*
13)不間斷巡邏各站就是路過(guò)
210.72.225.*
14)沙盒或者有被K站
123.125.68.*、218.30.118.102、220.181.68.*
15)此ip爬過(guò)的文章或首頁(yè),絕對(duì)24小時(shí)內(nèi)放出來(lái)和隔夜快照
220.181.108.*
16)百度蜘蛛IP來(lái)過(guò),準(zhǔn)備抓取
123.125.66.*、220.181.7.*
17)度過(guò)新站考察期
121.14.89.*
18)百度抓取首頁(yè)的專用IP,網(wǎng)站首頁(yè)快照更新快,隔夜更新
220.181.108.95
19)百度的權(quán)重IP段,抓取的文章第二天放出來(lái),權(quán)重較高
220.181.108.92
20)綜合性權(quán)重IP,抓取文章和首頁(yè),權(quán)重較高
220.181.108.91、220.181.108.75
21)抓取內(nèi)頁(yè)收錄的,但權(quán)重較低
123.125.71.95、123.125.71.97、123.181.108.77、123.125.71.106
22)抓取網(wǎng)站首頁(yè)的,也屬于權(quán)重段,權(quán)重較高。
220.181.108.89、220.181.108.94、220.181.108.97、220.181.108.80、220.181.108.77、220.181.108.83、220.181.108.86
在了解百度蜘蛛的各種IP分段后,我們就可以使用正則表達(dá)式將普通訪客和百度蜘蛛訪問(wèn)記錄區(qū)分開(kāi),甚至弄清楚具體哪個(gè)蜘蛛來(lái)訪是干什么的。這對(duì)于網(wǎng)站管理員了解網(wǎng)站流量和指導(dǎo)seo優(yōu)化非常具有參考價(jià)值,解開(kāi)長(zhǎng)久以來(lái)的疑惑“這些訪客是什么情況?”、“有沒(méi)有百度蜘蛛來(lái)爬行我的網(wǎng)站?”、“這個(gè)頁(yè)面有蜘蛛爬行但是未收錄”……,我們還可以通過(guò)站長(zhǎng)工具了解某個(gè)IP是否是真實(shí)的百度蜘蛛
百度蜘蛛喜歡什么?
搜索引擎喜歡的百度蜘蛛也不例外。(1)超級(jí)鏈接,不管是內(nèi)鏈還是外鏈都能一定程度增加內(nèi)容的權(quán)重,超級(jí)連接所在頁(yè)面的權(quán)重以及外鏈個(gè)數(shù)增多都能增加內(nèi)容的權(quán)重。(2)內(nèi)容原創(chuàng)度,一篇好的文章需要較高的原創(chuàng)度、字?jǐn)?shù)達(dá)到1000字以上,TDK相關(guān)性強(qiáng)等條件。(3)網(wǎng)站上線時(shí)間長(zhǎng),百度蜘蛛偏好上線時(shí)間長(zhǎng)的網(wǎng)站,同等條件下這類網(wǎng)站的權(quán)重更高更容易被收錄。(4)內(nèi)容更新頻繁,有規(guī)律高頻更新網(wǎng)站更容易吸引百度蜘蛛。
聲明:本文內(nèi)容可能屬于摘抄或轉(zhuǎn)載。若發(fā)現(xiàn)本站文章存在版權(quán)問(wèn)題,如發(fā)現(xiàn)文章、圖片等侵權(quán)行為,請(qǐng)聯(lián)系我們刪除。

